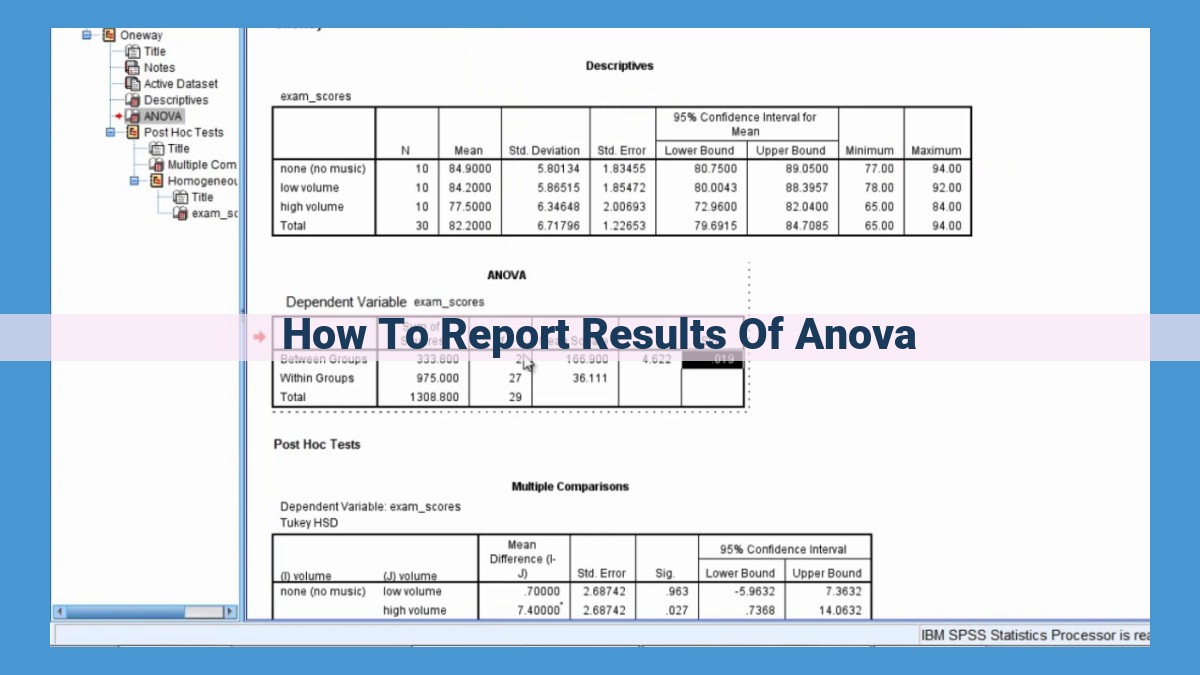
To report ANOVA results effectively, start by presenting the ANOVA table, highlighting the degrees of freedom, F-statistic, and p-value. Describe how the F-statistic reflects the ratio of between-group variance to within-group variance. Discuss main effects to show the influence of individual variables and interaction effects to reveal the joint effect of variables. Utilize the p-value to determine statistical significance and use post hoc tests for further analysis. Finally, summarize the results and provide insights for future research or applications.
Imagine yourself as a detective investigating the enigmatic case of group differences. Your trusty tool? ANOVA, the Analysis of Variance. This statistical sleuthing technique lets you crack the case wide open, revealing whether there are significant disparities lurking within your data.
ANOVA is like a mathematical magnifying glass, allowing you to probe the variance within your data, which is the spread or variability between different observations. By analyzing this variance, you can determine the influence of one or more independent variables on a dependent variable.
For instance, let’s say you’re investigating the impact of study techniques on exam performance. You divide your students into groups that practice spaced repetition, flashcards, or no specific technique. ANOVA will help you unravel whether the different study methods lead to statistically significant differences in exam scores.
Understanding the ANOVA Table: Dissecting the Data
When analyzing the results of an ANOVA, the ANOVA table takes center stage. It houses a wealth of information that helps us understand the overall significance of the results.
The ANOVA table consists of several key components:
Degrees of Freedom (df): This number represents the number of independent observations in each group and the number of independent comparisons being made. It plays a crucial role in determining the shape of the F-distribution and the significance of the F-statistic.
F-statistic: The F-statistic is a ratio that compares the variance between groups to the variance within groups. A larger F-statistic indicates that there is a greater difference between the group means.
p-value: The p-value is the probability of observing the F-statistic, assuming the null hypothesis is true (i.e., there is no difference between the group means). A smaller p-value (typically less than 0.05) means that the observed differences between groups are unlikely to be due to chance.
To interpret the ANOVA table, we first examine the p-value. If the p-value is less than our chosen level of significance (usually 0.05), we reject the null hypothesis and conclude that there is a statistically significant difference between the group means.
Next, we look at the F-statistic. A larger F-statistic indicates a greater difference between the group means. The F-statistic is calculated by dividing the variance between groups by the variance within groups. A large F-statistic suggests that the variance between groups is much larger than the variance within groups, making it more likely that the differences between group means are meaningful.
The ANOVA table provides us with a powerful tool for understanding the overall significance of our results. By carefully examining the degrees of freedom, F-statistic, and p-value, we can determine whether there is sufficient evidence to support our hypothesis and reject the null hypothesis.
Degrees of Freedom: The Key to ANOVA Significance
Imagine you’re at a party with a group of friends. You want to conduct a friendly experiment to determine who has the quickest reflexes. You decide to play a game where each person has to rapidly press a button when a light flashes. The person with the shortest time interval between the light flashing and button-pressing wins.
Now, let’s say there are four people participating in the game. Each person has one degree of freedom, representing their individual response time. So, in total, there are four degrees of freedom. This is because each person’s response time is independent of the others.
The degrees of freedom become critical when calculating the F-statistic, which measures the ratio of variance between groups (in this case, different individuals) to variance within groups (the variability of individual response times within each group).
The F-distribution, a bell-shaped curve, is used to determine the significance of the F-statistic. The degrees of freedom for the numerator and denominator of the F-ratio play a crucial role in determining the shape of the F-distribution.
With more degrees of freedom, the F-distribution becomes flatter and wider. This means that a higher F-statistic is required to achieve statistical significance. Conversely, with fewer degrees of freedom, the F-distribution becomes steeper and narrower, making it easier to reach significance with a lower F-statistic.
Understanding degrees of freedom is essential for accurately interpreting ANOVA results. It helps researchers determine the critical value of the F-statistic and the corresponding p-value. This allows them to make informed decisions about the statistical significance of their findings. Without considering degrees of freedom, the interpretation of ANOVA results would be incomplete and potentially misleading.
The Enigmatic F-Distribution: A Tale of Variances
In the realm of statistical analysis, there exists an enigmatic distribution that holds the key to understanding the variability of data. Meet the F-distribution, a fascinating curve that plays a pivotal role in uncovering the intricacies of data.
Picture this distribution as a bell-shaped curve, similar to the normal distribution you may be familiar with. However, the F-distribution has a unique characteristic that sets it apart. Unlike the normal distribution, which is symmetrical around its mean, the F-distribution is positively skewed, meaning it extends further to the right.
This skewness arises from the fact that the F-distribution is a ratio of two chi-square distributions, each with a different number of degrees of freedom. The number of degrees of freedom determines the width or “spread” of the distribution. The higher the degrees of freedom, the narrower the distribution becomes.
The shape of the F-distribution is crucial in hypothesis testing. In ANOVA (Analysis of Variance), the F statistic is used to test whether there are significant differences between group means. The F statistic compares the variance between groups (the numerator) to the variance within groups (the denominator).
If the F statistic is large, it indicates that there is a greater discrepancy between group means compared to the variation within groups. This suggests that the independent variable(s) have a significant effect on the dependent variable.
Conversely, if the F statistic is small, it implies that the group means are not significantly different from each other. In such cases, we conclude that the independent variable(s) have no discernible impact on the dependent variable.
The F-distribution is a mathematical marvel that helps us unveil the subtle nuances of data. By understanding its shape and characteristics, we gain the power to interpret the results of ANOVA and make informed decisions about our research findings.
Interpreting the F-Statistic: Unlocking the Significance of ANOVA Results
The F-statistic stands as a pivotal figure in the realm of ANOVA (Analysis of Variance), serving as an indicator of the significance of differences between group means. Understanding its calculation and interpretation is crucial for deciphering the insights hidden within ANOVA results.
The F-statistic is calculated as the ratio of the variance between groups to the variance within groups. Variance between groups represents the variability of group means, while variance within groups captures the variability of individual data points within each group. A larger F-statistic signifies a greater disparity between group means relative to the variation within groups.
The F-statistic plays a central role in determining the probability of observing the obtained differences between groups, assuming the null hypothesis of no group differences is true. It is used to calculate the p-value, which represents the likelihood of obtaining an F-statistic as extreme as the one observed, given the null hypothesis.
By comparing the F-statistic to the critical value of the F-distribution with appropriate degrees of freedom, researchers can determine whether the obtained differences between group means are statistically significant. A significant F-statistic (p < 0.05) suggests that the observed differences are unlikely to have occurred by chance alone and that there is evidence for rejecting the null hypothesis.
The F-statistic, therefore, provides a quantitative measure of the strength of evidence against the null hypothesis. It guides researchers in making informed decisions about the existence of significant differences between groups, allowing them to draw meaningful conclusions from their ANOVA analyses.
Understanding Main Effects: The Impact of Independent Variables
In the realm of data analysis, ANOVA (Analysis of Variance) emerges as a powerful tool to compare multiple groups and uncover significant differences among them. At the heart of ANOVA lies the concept of main effects, providing insights into the influence of individual independent variables on the dependent variable.
Defining Main Effects
Main effects represent the direct impact of each independent variable on the dependent variable. They indicate whether the differences between group means are statistically significant. In other words, main effects tell us how much of the variation in the dependent variable is explained by each independent variable.
Interpreting Main Effects
To interpret main effects, we look at the ANOVA table, which lists the F-statistic and p-value for each independent variable. A significant p-value (typically less than 0.05) indicates that the main effect is statistically significant.
If the main effect is significant, it means that the independent variable has a measurable effect on the dependent variable. For example, if you’re analyzing the impact of two fertilizers on plant growth, a significant main effect for fertilizer would indicate that the different fertilizers have different effects on plant height.
Emphasizing the Importance
Main effects are crucial because they reveal the independent effect of each variable on the outcome. They help us understand how each variable contributes to the overall variation in the dependent variable. Moreover, main effects form the foundation for exploring interaction effects, which reveal how multiple independent variables interact to influence the outcome.
Example
Consider a study examining the relationship between gender and income. The ANOVA table shows a significant main effect for gender, indicating that there is a statistically significant difference in income between men and women. This means that gender has a direct and independent effect on income.
Main effects provide valuable insights into the individual impact of independent variables on the dependent variable. They help us identify significant relationships and lay the groundwork for further analysis. By understanding main effects, researchers can gain a comprehensive understanding of the factors influencing a particular outcome.
Exploring the Nuances of Interaction Effects in ANOVA
Imagine you’re conducting an experiment to investigate the effect of two factors, fertilizer type and soil temperature, on plant growth. ANOVA is an invaluable tool for teasing out the influence of each factor and any potential interplay between them.
Defining Interaction Effects
When ANOVA reveals a statistically significant interaction effect, it indicates that the effect of one factor on the dependent variable depends on the level of another factor. For instance, if you find an interaction effect between fertilizer type and soil temperature, it means that the growth-boosting effect of a particular fertilizer depends on the soil temperature.
Interpreting Interaction Effects
To interpret interaction effects, we examine the joint effect of both factors on the dependent variable. For example, let’s say that a specific fertilizer promotes faster growth in warm soil but inhibits growth in cold soil. This interaction effect highlights the critical role of both soil temperature and fertilizer type in determining plant growth patterns.
Unveiling Hidden Connections
Interaction effects reveal hidden connections and complexities within your data. They demonstrate that the effects of one factor are not always constant but can be influenced by the levels of other factors. Understanding these interactions is essential for making informed conclusions about the relationships between the variables in your study.
Practical Implications
Interaction effects have practical implications in various fields. In agriculture, they guide farmers in selecting optimal fertilizer combinations and soil management practices based on specific climatic conditions. In medicine, they help researchers tailor treatments to individual patients based on genetic and environmental factors.
By exploring interaction effects, we gain a more profound understanding of the phenomena we study. They illuminate the intricate relationships between variables, enabling us to make more accurate predictions and optimize outcomes in diverse domains.
Significance and the p-Value
In the world of statistics, the p-value holds immense significance, akin to a jury’s verdict in a courtroom. It represents the probability of observing a test statistic, like the F-statistic in ANOVA, assuming the null hypothesis is true. A low p-value means that the observed data is highly unlikely to have occurred by chance alone.
When conducting hypothesis testing, researchers establish a significance level, typically set at 0.05 or 0.01. This signifies that any p-value below the significance level leads to the rejection of the null hypothesis. In other words, there is sufficient evidence to suggest that the observed differences between groups are not simply due to random chance.
Conversely, a p-value above the significance level indicates failure to reject the null hypothesis. This implies that while the observed differences between groups may exist, they are not statistically significant, and the data cannot conclusively support the alternative hypothesis.
It’s crucial to note that statistical significance does not equate to practical significance. A small difference between groups may be statistically significant but may not have any meaningful impact in the real world. Researchers must carefully consider both statistical and practical significance when interpreting their results.
Post Hoc Tests: Digging Deeper into ANOVA Results
After conducting an analysis of variance (ANOVA) and obtaining a significant result, researchers often seek to identify which specific groups differ from each other. This is where post hoc tests come into play.
What are Post Hoc Tests?
Post hoc tests are statistical procedures that allow researchers to compare the means of individual groups after an overall ANOVA test has indicated that there is a significant difference between the groups. In other words, post hoc tests help to pinpoint the precise sources of the overall group differences.
Why Use Post Hoc Tests?
ANOVA tests provide an overall assessment of whether there is a significant difference between the groups. However, they do not tell us which specific groups are responsible for the difference. Post hoc tests are used to conduct pairwise comparisons between individual groups to identify the specific differences.
Types of Post Hoc Tests
There are several different types of post hoc tests, each with its own strengths and weaknesses. Some common post hoc tests include:
- Tukey’s Honest Significant Difference (HSD) test
- Scheffé’s test
- Bonferroni correction
The choice of post hoc test depends on factors such as the number of groups being compared, the sample size, and the desired level of significance.
Interpreting Post Hoc Test Results
The results of post hoc tests are typically presented in a table, which shows the p-values for each pairwise comparison. A significant p-value (<0.05) indicates that there is a statistically significant difference between the means of the two groups being compared.
Example
Suppose you conducted an ANOVA to compare the average test scores of students who studied using three different teaching methods. The ANOVA test yielded a significant result, indicating that there is a difference in test scores between the three groups. To determine which groups are different from each other, you would use a post hoc test.
If the Tukey’s HSD test was used as the post hoc test, and the results showed a significant p-value between Group A and Group B, it would mean that the average test score of Group A is statistically significantly different from the average test score of Group B.
Interpreting a Significant ANOVA Result
At this juncture, we delve into the interpretation of a statistically significant ANOVA result, a pivotal moment in the analysis. A significant result is a beacon of information, illuminating the presence of significant differences among your cherished experimental groups. It is a triumphant affirmation that your data holds a tale worth telling.
This significance unveils the existence of variations that are not attributable to mere chance. It signifies that the independent variable under investigation has wielded a tangible impact on the dependent variable, leaving an imprint on the outcomes observed. This revelation empowers researchers to conclude that the observed differences are not simply a figment of random fluctuations but rather the fruit of meaningful group disparities.
The significance unearthed by ANOVA acts as a springboard for further exploration. It invites researchers to embark on a deeper dive, utilizing post hoc tests to pinpoint the specific groups that contribute to the overall variance. These tests serve as detectives, meticulously examining the data to uncover the precise source of significant differences.
The significance of an ANOVA result is a milestone in the research journey, paving the path towards a more nuanced understanding of the relationships between variables. It is a pivotal moment that sparks further investigation, enriching our comprehension of the phenomena under scrutiny.
