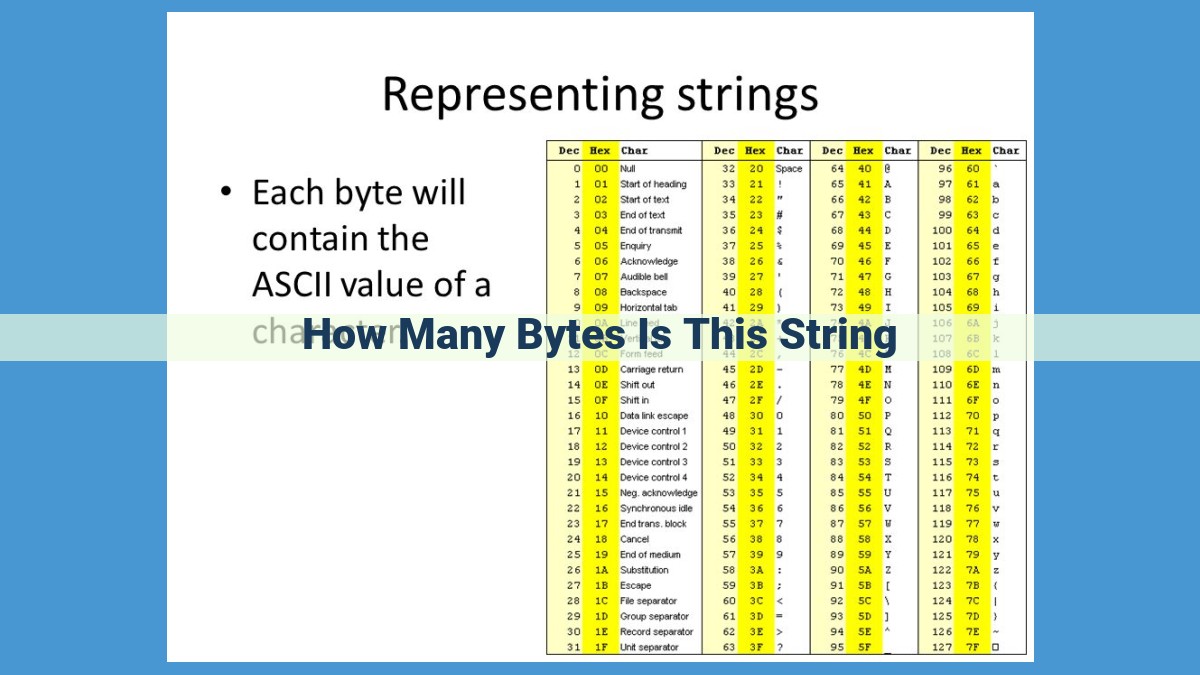
To determine the number of bytes in a string, we first consider its length and character encoding. Character encoding, such as Unicode, defines how characters are represented digitally. Unicode uses variable-length encoding, meaning characters can occupy varying numbers of bytes. The three common Unicode encodings are UTF-8, UTF-16, and UTF-32, each with distinct byte counts per character. To calculate the number of bytes in a string, we multiply the string length by the number of bytes per character, as specified by the encoding used. For example, a 10-character string encoded in UTF-8, where characters typically occupy 1 byte, would result in 10 bytes. Understanding these concepts helps us accurately determine the size of a string in bytes, which is crucial for various computing applications.
Explain the concept of string length and its significance in calculating bytes.
Title: The Byte Count Quandary: Unraveling the Mystery of String Length and Character Encoding
The Curious Case of String Length and Bytes
In the digital realm, where information flows in endless streams, understanding the intricacies of data storage is paramount. One fundamental concept that often evokes puzzlement is the relationship between string length and the number of bytes it consumes.
A string, an ordered sequence of characters, forms the backbone of our written communication in the digital world. The length of a string refers to the number of characters it contains. However, when it comes to determining the amount of space it occupies in memory, another factor steps into the limelight: character encoding.
Understanding Character Encoding
Character encoding determines how characters are represented in digital form. The most widely used encoding scheme is Unicode, a universal standard that assigns a unique numerical value to every character from various languages and alphabets. These numerical values, when translated into binary form, dictate the number of bytes required to store a particular character.
The Essence of a Byte: A Digital Building Block
A byte, the fundamental unit of digital information, consists of eight binary digits, or bits. In the realm of character storage, the number of bytes required to represent a character depends on the character encoding scheme employed.
Unicode Encodings: The Byte-Character Dance
Unicode offers three primary encodings: UTF-8, UTF-16, and UTF-32. Each encoding varies in how it assigns bytes to characters:
- UTF-8: Utilizes variable-length encoding, assigning 1 to 4 bytes per character. Its flexibility makes it suitable for storing text in multiple languages.
- UTF-16: Generally uses 2 bytes per character, catering specifically to languages with characters written in two-byte sequences.
- UTF-32: Employs a fixed-length encoding of 4 bytes per character, ensuring compatibility with all Unicode characters.
Unveiling the Byte Count Secret
Calculating the number of bytes in a string involves two crucial factors: string length and character encoding. By multiplying the string length with the number of bytes per character (determined by the encoding scheme), we can determine the total byte count.
An Illustrative Example
Consider a text string of 100 characters encoded in UTF-8. Since UTF-8 uses variable-length encoding, the maximum possible number of bytes is 400 (100 characters × 4 bytes per character). However, the actual byte count may be lower if the string contains characters that require fewer bytes.
Beyond the Basics: Additional Considerations
While the fundamental principles remain the same, there are potential factors that can influence byte count calculation:
- Byte Order and Endianness: The order in which bytes are stored in memory can affect the byte count.
- Exceptions and Non-Standard Encodings: Some characters may require special handling or non-standard encodings, leading to variations in byte count.
In essence, understanding the interplay between string length and character encoding empowers us to accurately determine the digital footprint of our text, paving the way for efficient data management and communication.
Introduce the importance of character encoding and its impact on byte count.
Character Encoding: The Invisible Force Shaping Your Digital World
Every character you type, every word you write, exists in the digital realm as a sequence of numbers. These numbers represent the letters, symbols, and punctuation that we use to communicate, but they don’t tell the whole story. Behind these numbers lies a fundamental concept that plays a crucial role in determining how much space your digital content occupies: character encoding.
Character encoding is the process of assigning a unique number to each character in a defined set. This set of characters is known as a character set, and it serves as a dictionary of sorts, translating human-readable characters into their digital counterparts. Different character sets exist, catering to different languages, cultures, and specialized domains.
The significance of character encoding lies in its impact on byte count. In the world of digital computing, information is stored in units called bytes. A byte is a sequence of eight bits, and each bit can be either a 0 or a 1. By combining these bits in different ways, we can create different numerical values, which in turn represent different characters.
The choice of character encoding affects how many bytes are required to represent each character. Some character sets, such as ASCII (American Standard Code for Information Interchange), use only 7 bits to represent each character, while others, such as Unicode, can use up to 32 bits per character. This difference in bit count directly translates to a difference in byte count.
For example, if you have a string of 10 characters encoded in ASCII, it will occupy 70 bits or 8.75 bytes. However, if the same string is encoded in Unicode using UTF-8 (8-bit encoding), it will occupy 80 bits or 10 bytes.
Understanding the concept of character encoding is essential for optimizing your digital content for space and efficiency. By choosing the right character encoding, you can minimize the byte count of your data, making it more efficient to store, transmit, and process.
Discuss the role of Unicode in character representation.
Understanding the Role of Unicode in Character Representation
In the vast tapestry of digital communication, characters serve as the building blocks of meaning, expressing our thoughts and ideas. However, these characters can vary greatly in their complexity, from simple ASCII letters to intricate Chinese ideograms. This diversity poses a challenge: how do we represent such a wide range of characters in a standardized way that computers can understand?
Enter Unicode, a universal character encoding standard that assigns a unique numeric value to every character in every written language. This allows computers to process and display text regardless of the language or platform. Unicode’s vast character set encompasses not only the Latin alphabet but also characters from Arabic, Chinese, Japanese, and countless other writing systems.
Unicode’s strength lies in its variable-length encoding, meaning that characters are represented by a varying number of bits. Simple characters like “a” or “1” can be encoded in as few as 8 bits, while more complex characters like Chinese ideograms may require 16 or even 32 bits. This flexible approach optimizes storage and transmission efficiency while ensuring that all characters can be represented faithfully.
By providing a common language for character representation, Unicode has made it possible for us to communicate and exchange text seamlessly across different platforms, languages, and devices. It has broken down linguistic barriers and facilitated global communication, empowering us to share ideas and connect with people from all over the world.
Section 2: Understanding Character Encoding
Variable-Length Encoding and Its Impact on Byte Count
The concept of variable-length encoding plays a crucial role in determining the byte count of a string. Unlike fixed-length encoding, where each character occupies a predetermined number of bytes, variable-length encoding adapts to the specific needs of each character.
In variable-length encoding schemes like Unicode, multi-byte characters (such as those from non-English alphabets or special symbols) occupy more bytes than single-byte characters (e.g., English lowercase and uppercase letters). This is because multi-byte characters require multiple bytes to represent their complex codepoints.
For instance, in UTF-8 encoding, a single-byte character like “a” requires only 1 byte, while a multi-byte character like “€” (the Euro symbol) may require 2 bytes. This flexibility in byte allocation optimizes space utilization by assigning more bytes to characters that need them, while conserving bytes for simpler characters.
As a result, variable-length encoding can significantly affect the byte count of a given string, especially when dealing with non-ASCII characters. This understanding is essential for accurate byte count calculations and efficient storage and transmission of text data.
Understanding Byte Count: A Comprehensive Guide for Digital Media
In the realm of digital technology, understanding the concept of byte count is crucial for optimizing data storage and transmission. Bytes, the fundamental units of digital information, play a pivotal role in determining the size of text, images, and other digital assets. This article will delve into the intricacies of byte count calculation, exploring the concepts of string length, character encoding, and the various Unicode encodings.
String Length and Character Encoding
Every character in a string occupies a specific amount of space, known as its length. This length, measured in characters, is not directly related to the number of bytes required to represent the string. Character encoding comes into play here, as different encodings use varying numbers of bytes to represent each character.
The Byte: A Building Block of Digital Information
A byte, the cornerstone of digital data, comprises 8 bits, which are the smallest units of information. Every byte can represent a value ranging from 0 to 255, making it ideal for storing and processing a vast array of data.
Unicode Encodings: A Tale of Bytes and Characters
Unicode, the universal character encoding standard, ensures the consistent representation of characters across different platforms and languages. Unicode supports a wide range of encodings, with the most common being UTF-8, UTF-16, and UTF-32.
-
UTF-8: A variable-length encoding that uses 1 to 4 bytes per character.
-
UTF-16: A variable-length encoding that primarily uses 2 bytes per character but may use 4 bytes for certain characters.
-
UTF-32: A fixed-length encoding that always uses 4 bytes per character.
Calculating the Byte Count: A Step-by-Step Guide
-
Determine the String Length: Count the number of characters in the string.
-
Identify the Character Encoding: Determine the encoding scheme used for the string, as it affects the number of bytes per character.
-
Multiply by Bytes per Character: Multiply the string length by the number of bytes per character for the chosen encoding.
Example: Determining Bytes in a UTF-8 String
Consider a string with a length of 10 characters encoded in UTF-8. UTF-8 typically uses 1 byte for each character, making the maximum possible byte count:
10 characters x 1 byte/character = 10 bytes
Additional Considerations: Nuances of Byte Count
While the formula above provides a general approach, there are certain factors that can influence byte count calculation:
-
Byte Order: The arrangement of bytes within a multi-byte character (e.g., UTF-16, UTF-32).
-
Endianness: The order in which bytes are stored within a multi-byte word (e.g., little-endian vs. big-endian).
Understanding these nuances is important for accurate byte count determination in specific contexts.
Explain the relationship between bytes and the size of characters.
The Byte: A Unit of Digital Expression
In the digital realm, characters dance across our screens, each carrying meaning within their tiny forms. Behind the scenes, these characters are represented by a fundamental unit of information: the byte. A byte, composed of eight bits, acts as a building block for digital communication and data storage.
The relationship between bytes and the size of characters is a crucial aspect to understand. In the simplest terms, the size of a character, or the number of bytes it occupies, is determined by the character encoding used. Character encoding is a method of representing characters using a specific sequence of bits.
Different character encodings exist, such as ASCII (American Standard Code for Information Interchange), which assigns 7 bits to represent characters. ASCII is a commonly used encoding that supports basic Latin characters. However, with the advent of multilingual computing, more sophisticated encodings like Unicode emerged. Unicode, which provides a wider range of characters from various languages and scripts, employs variable-length encoding.
Unicode character encodings, such as UTF-8, UTF-16, and UTF-32, use a varying number of bytes to represent characters. UTF-8, a widely adopted encoding, represents most characters using one or two bytes. Meanwhile, UTF-16 typically uses two bytes per character, while UTF-32 uses four bytes per character.
Knowing the relationship between bytes and character size is essential for various applications. For example, when transmitting or storing text data, it’s crucial to consider the number of bytes required based on the character encoding used. Furthermore, in programming languages, understanding byte size is critical for efficient memory allocation and data handling.
The Byte Chronicles: Unveiling the Mysteries of String Length and Character Encoding
In the realm of digital communication, where thoughts and ideas traverse the ethereal expanse of the internet, the underlying mechanisms of data representation often remain shrouded in obscurity. One such enigma is the interplay between string length, character encoding, and that enigmatic entity known as the byte. Let us embark on an enlightening journey to demystify this intricate relationship.
The Puzzle of String Length
A string, the digital embodiment of text, is a sequence of characters that convey meaning. Each character, будь то a letter or a symbol, occupies a specific position within the string, and the total number of characters constitutes its length. This seemingly straightforward concept, however, becomes more nuanced when we delve into the realm of character encoding.
Character encoding is the art of representing characters in a digital format. Different encoding schemes assign different bit patterns to each character, resulting in varying byte counts. Understanding this relationship is crucial for accurately calculating the number of bytes required to store a given string.
A Tale of Three Encodings: UTF-8, UTF-16, and UTF-32
In the vast tapestry of Unicode encodings, three titans stand out: UTF-8, UTF-16, and UTF-32. Each encoding employs a unique strategy to represent characters, resulting in distinct byte counts. UTF-8 is the most commonly used encoding, opting for variable-length encoding, where each character can be represented by one to four bytes. UTF-16 utilizes fixed-length encoding, using two bytes per character, while UTF-32 employs fixed-length encoding, allocating a generous four bytes per character. The choice of encoding depends on the specific requirements of the application and the nature of the characters being encoded.
Unveiling the Formula: Calculating String Length in Bytes
To determine the number of bytes consumed by a string, we must consider both its length and the character encoding employed. The following formula serves as our guide:
Number of Bytes = String Length * Bytes per Character
Where “Bytes per Character” is determined by the chosen encoding (UTF-8, UTF-16, or UTF-32).
A Practical Example: UTF-8 in Action
Let us consider a string of length 10 encoded in UTF-8. As UTF-8 employs variable-length encoding, the maximum possible byte count is 40 (10 characters * 4 bytes per character). Since UTF-8 favors efficiency, it is likely that the actual byte count will be lower, but without knowing the specific characters in the string, we cannot determine the exact number of bytes.
Additional Considerations in the Realm of Bytes
While the formula provides a solid foundation for byte count calculation, there exist additional factors that may introduce complexities:
- Byte Order: The arrangement of bits within a byte can vary, known as endianness.
- Supplementary Characters: Certain characters, such as emojis, require multiple code points to be represented, potentially affecting byte count.
Understanding the interplay between string length, character encoding, and bytes empowers us to navigate the digital realm with greater precision. By embracing these concepts, we become scribes of the digital age, capable of crafting and deciphering the myriad messages that flow through the boundless expanse of cyberspace.
How to Calculate the Number of Bytes in a String
In the digital realm, strings are ubiquitous. From emails to databases, they carry vital information that shapes our online experiences. Understanding the underlying mechanics of strings, including their byte count, is crucial for optimizing data storage and processing. This blog post will guide you through the intricacies of string length, character encoding, and byte calculation.
Understanding String Length and Character Encoding
Every string has a length, which represents the number of characters it contains. Character encoding comes into play when representing these characters in binary form. Unicode is the standard for global character representation, and its implementation through encodings like UTF-8, UTF-16, and UTF-32 determines the number of bytes required per character.
Variable-Length Encoding and Bytes
Bytes are fundamental units of digital information, each consisting of 8 bits. The relationship between bytes and strings is governed by character encoding. Variable-length encodings like UTF-8 adjust the number of bytes per character based on its complexity, minimizing space usage for frequently used characters.
Unicode Encodings and Bytes per Character
UTF-8, UTF-16, and UTF-32 are the three primary Unicode encodings, each with distinct byte requirements per character. UTF-8 is commonly used in web development and encodes most characters in 1 byte. UTF-16 uses 2 bytes per character, while UTF-32 allocates 4 bytes per character, supporting a wider range of characters.
Calculating the Number of Bytes in a String
To calculate the number of bytes in a string, you need to know its length and character encoding. For example, a string with a length of 100 and UTF-8 encoding could have a maximum byte count of 100 (assuming all characters are single-byte encoded). However, factors like multi-byte characters and byte order can influence the actual byte count.
Example: UTF-8 Byte Calculation
Consider the string “Hello, world!” with UTF-8 encoding. Each character occupies 1 byte, except for the exclamation mark, which requires 2 bytes. The total byte count is 13 (12 for ASCII characters + 2 for the exclamation mark).
Additional Considerations
Beyond the basics, other factors can affect byte count calculation, such as endianness (byte order) and the presence of non-Unicode characters. Understanding these nuances is essential for accurate byte calculations in real-world applications.
Present a step-by-step formula for calculating the number of bytes in a string.
Understanding Bytes and Strings: A Guide to Calculating Byte Count
In the realm of digital communication, bytes play a crucial role as the fundamental units of information storage. Strings, which are sequences of characters, also have a byte count that depends on their length and the encoding used to represent the characters.
String Length and Character Encoding
The length of a string refers to the number of characters it contains. This is a critical factor in determining the byte count because different characters can require different numbers of bytes to represent them. The encoding used to represent the characters further influences the byte count.
Understanding Character Encoding
Unicode, a universal character encoding standard, provides a unique code for every character, regardless of language or script. Different Unicode encodings, such as UTF-8, UTF-16, and UTF-32, vary in the number of bytes used to encode a character.
The Byte: A Unit of Digital Information
A byte is a unit of digital information composed of 8 bits. It is the smallest addressable unit of storage in a computer system. The size of a character, in terms of bytes, depends on the character encoding used.
Unicode Encodings: UTF-8, UTF-16, UTF-32
- UTF-8: A variable-length encoding that uses 1-4 bytes per character. It is widely used on the internet and supports a large range of languages.
- UTF-16: A variable-length encoding that uses 2-4 bytes per character. It is commonly used in Windows systems.
- UTF-32: A fixed-length encoding that uses 4 bytes per character. It is most commonly used in applications that require high precision in character representation.
Calculating the Number of Bytes in a String
To calculate the number of bytes in a string, follow these steps:
- Determine the length of the string (number of characters).
- Identify the character encoding used.
- Refer to the encoding table to determine the maximum number of bytes per character.
- Multiply the maximum bytes per character by the string length.
Example: Determining Bytes in a UTF-8 String
Consider a UTF-8 string with a length of 10 characters. The maximum bytes per character for UTF-8 is 4.
- Maximum bytes per character: 4
- String length: 10
- Byte count: 4 * 10 = 40 bytes
Additional Considerations
- Byte Order: The order of bytes within a multi-byte character can vary depending on the system architecture (big-endian or little-endian).
- Endianness: The way in which bytes are ordered within a multi-byte word can affect the byte count.
- Non-Unicode Characters: Characters outside the Unicode standard may require more bytes to represent.
**Understanding the Bytes Behind Your Strings: A Comprehensive Guide**
Strings, those sequences of characters that form the building blocks of our digital communication, are not as straightforward as they seem. Behind the scenes, they carry a hidden dimension that affects how they’re stored and processed: byte count.
To understand byte count, we need to delve into the fundamentals of strings. Their length refers to the number of characters they contain. This may seem simple, but it’s only half the story. The other crucial factor is character encoding, which determines how each character is represented digitally.
Character Encoding: The Invisible Force Shaping Bytes
Character encoding translates characters into a binary format that computers can understand. Unicode, the universal standard, assigns a unique code point to every character. However, different Unicode encodings handle these code points differently. The three main encodings, UTF-8, UTF-16, and UTF-32, vary in their approach to character representation.
UTF-8, the most common encoding, uses a variable-length approach. It represents characters with a varying number of bytes (1 to 4), based on their code point. This efficiency makes UTF-8 ideal for storing multilingual text in a compact form. Contrast this with UTF-16, which typically uses 2 bytes per character, and UTF-32, which uses 4 bytes per character.
The choice of encoding significantly affects the byte count of a string. For example, a string that uses UTF-8 will likely occupy fewer bytes than the same string encoded in UTF-16 or UTF-32.
Therefore, to accurately calculate the byte count of a string, we need to know both its string length and character encoding. With this knowledge, we can apply a simple formula to determine the exact number of bytes it occupies digitally.
Understanding the Byte Count in Strings: Unveiling the Digital Information
1. String Length and Character Encoding: A Prelude
When working with strings, their length and the way characters are encoded are crucial in determining their byte count. String length refers to the number of characters, while character encoding defines the rules for representing characters as binary data. This intricate interplay greatly influences how many bytes a string occupies.
2. Exploring Character Encoding and Its Impact
Unicode emerged as the universal standard for character representation, encompassing a vast array of languages and scripts. However, different Unicode encodings exist, and their choice affects the number of bytes required per character. For instance, UTF-8 is a variable-length encoding, meaning it can use one or more bytes per character, depending on its complexity.
3. The Byte: The Building Block of Digital Data
A byte serves as the fundamental unit of digital information. Comprising eight bits, each byte holds a numeric value between 0 and 255. Understanding the relationship between bytes and characters is essential for accurately gauging the byte count of a string.
4. Unveiling the Unicode Encodings: UTF-8, UTF-16, and UTF-32
UTF-8 reigns as the most commonly used Unicode encoding, with each character consuming one to four bytes. UTF-16 employs two bytes per character, while UTF-32 reserves four bytes for every character. These variations in byte allocation directly impact the overall byte count of strings.
5. Calculating the Bytes in a String: A Step-by-Step Guide
Determining the byte count of a string involves a simple formula: Byte count = String length * Bytes per character. To apply this formula effectively, you must know both the string length and the applicable character encoding.
6. Example: Demystifying the Byte Count in a UTF-8 String
Consider a string with a length of 10 characters, encoded in UTF-8. Since UTF-8 uses variable-length encoding, the maximum possible byte count for this string is 10 * 4 = 40 bytes. However, the actual byte count could be lower, depending on the specific characters used.
7. Additional Considerations for Byte Count Calculation
While the formula provides a solid foundation for calculating byte count, there are potential exceptions and challenges to consider:
- Byte Order: Computers store bytes in different orders (big-endian or little-endian), which can affect the byte count calculation.
- End-of-Line Characters: Certain operating systems and programming languages use special characters to denote the end of a line. These characters can add to the byte count.
The Enigma of Bytes: Unveiling the Hidden Secrets of Strings
In the digital realm, where information flows like a river, one crucial element stands out: bytes. These tiny units, composed of eight bits, form the foundation of our digital world, encoding everything from text to images. But what exactly are bytes, and how do they relate to the strings we encounter in our daily online adventures? Let’s unravel this mystery!
String Length and Character Encoding: The Puzzle Pieces
Every string, whether a paragraph or a single character, has a length. This length represents the number of characters in the string, but it’s not as straightforward as you might think. The length of a string depends on the character encoding used, which determines how many bytes are required to represent each character.
Understanding Character Encoding: The Invisible Translator
Character encoding plays a pivotal role in converting human-readable characters into a form that computers can understand. Unicode, a universal character set, assigns a unique code point to every character in the world’s languages. However, different encodings, such as UTF-8, UTF-16, and UTF-32, represent these code points using a varying number of bytes.
The Byte: The Building Block of Digital Information
A byte is a fundamental unit of digital information, consisting of eight bits. Each bit can be either 0 or 1, making it possible to represent 256 different values. This vast range allows bytes to encode a diverse array of data, including text, numbers, and images.
Unicode Encodings: The Versatile Cast of Characters
UTF-8 is the most widely used Unicode encoding, representing characters with one to four bytes. It’s optimized for English and other Western languages. UTF-16 uses two or four bytes per character, suitable for languages with larger character sets. UTF-32 allocates four bytes for each character, providing the most comprehensive coverage.
Calculating the Number of Bytes in a String: The Formula Revealed
To determine the number of bytes in a string, we multiply the string length by the number of bytes required per character. However, we must first know the character encoding used. For example, a string with a length of 10 characters encoded in UTF-8 could occupy up to 40 bytes.
Example: Counting Bytes in a UTF-8 String
Suppose we have a string of 100 characters encoded in UTF-8. Since UTF-8 uses a maximum of four bytes per character, the maximum possible number of bytes for this string is 100 × 4 = 400 bytes.
Additional Considerations: The Hidden Variables
While the above formula provides a basic framework for byte count calculation, there are a few additional factors to consider. Byte order and endianness can affect the way bytes are arranged within a data structure. It’s important to be aware of these nuances to ensure accurate calculations.
By understanding the concepts of string length, character encoding, and bytes, we gain a deeper appreciation for the intricacies of digital information. The ability to calculate the number of bytes in a string is not only a technical skill but also a valuable tool for optimizing data storage, transmission, and processing. Embrace the challenge and unlock the secrets of the enigmatic byte!
Discuss potential issues or exceptions that may affect byte count calculation.
Understanding Byte Count: Potential Issues and Exceptions
In the realm of digital information, understanding the relationship between characters and bytes is crucial for accurately calculating the size of strings. While the concepts outlined earlier provide a solid foundation, there are some potential issues and exceptions that may affect byte count calculation.
Character Encoding Variations
The encoding of a character can significantly impact the number of bytes it occupies. While the UTF-8, UTF-16, and UTF-32 encodings are widely used, there are other character encodings, each with its own rules for representing characters. An unrecognized or unsupported encoding can result in unexpected byte counts.
Byte Order and Endianness
In computer systems, bytes can be stored in different orders, known as byte order or endianness. The two main byte orders are little-endian and big-endian. Little-endian systems store the least significant byte of a multi-byte value at the lowest memory address, while big-endian systems do the opposite. This difference in byte order can affect the interpretation of bytes and, consequently, the byte count calculation.
Non-Character Data
Strings may sometimes contain non-character data, such as control characters or escape sequences. These non-character elements may not be represented in the same way as regular characters, leading to variations in byte count.
Unicode Normalization
Unicode normalization is a process that ensures consistency in the representation of Unicode characters. Different normalization forms (e.g., NFC, NFD) can result in different byte counts for the same string.
Additional Considerations
In some cases, the encoding of a string may not be explicitly defined or easily determined. This can lead to uncertainties in byte count calculation. Additionally, external factors, such as system settings and programming language implementations, can affect the way strings are handled and stored, potentially impacting byte count calculations.
Understanding these potential issues and exceptions is essential for accurate byte count calculations. By considering these factors, developers can ensure the reliable and consistent handling of strings and bytes in their applications.
Unlocking the Enigma: Bytes and Strings
In the realm of digital data, strings and bytes are two fundamental elements that serve as building blocks for our digital lives. Understanding the relationship between these two entities is crucial for accurately calculating the size of data and ensuring its efficient transmission and storage.
String Length and Character Encoding: The Foundation
Every string, a sequence of characters, has a length, which is the number of characters it contains. However, it’s not always as simple as it seems. Character encoding, the method used to represent characters as digital signals, plays a critical role in determining the number of bytes required to store a string.
Character Encoding: Unveiling the Secrets
Unicode, the international standard for character encoding, ensures that every character in the world’s written languages can be digitally represented. Variable-length encoding schemes like UTF-8, UTF-16, and UTF-32 are used to encode Unicode characters. Each character is assigned a varying number of bits depending on its complexity, leading to different byte counts for different strings.
The Byte: The Fundamental Unit
A byte, a group of 8 bits, is the basic unit of digital information. Characters, the building blocks of strings, are stored in bytes, with each character occupying one or more bytes depending on its character encoding.
Unicode Encodings: The Variations
UTF-8, UTF-16, and UTF-32 are the three primary Unicode encodings. UTF-8, widely used for its efficiency, encodes most characters using a single byte, while UTF-16 and UTF-32 use two and four bytes per character, respectively. The choice of encoding affects the number of bytes required to store a string.
Calculating Bytes in a String: A Step-by-Step Guide
Determining the number of bytes in a string involves knowing its length and character encoding. Using a simple formula, Bytes = Length * Bytes per Character, you can easily calculate the maximum possible number of bytes for a given string.
Example: Unveiling Bytes in a UTF-8 String
Consider a string with a length of 100 characters encoded using UTF-8. Since UTF-8 typically uses one byte per character, the maximum number of bytes for this string is 100. However, it’s important to note that this is a maximum, and the actual number of bytes may vary slightly.
Additional Considerations: Exploring the Complexities
While the basic principles remain the same, there are a few additional factors that can affect byte count calculations. Byte order, the sequence in which bits are arranged, and endianness, the order of bytes within a multi-byte character, can introduce complexities that require careful consideration.
Understanding the intricate relationship between strings and bytes empowers you with the knowledge to effectively manage digital data. From accurately calculating storage requirements to optimizing data transmission, this understanding forms the foundation for navigating the digital landscape with confidence.
