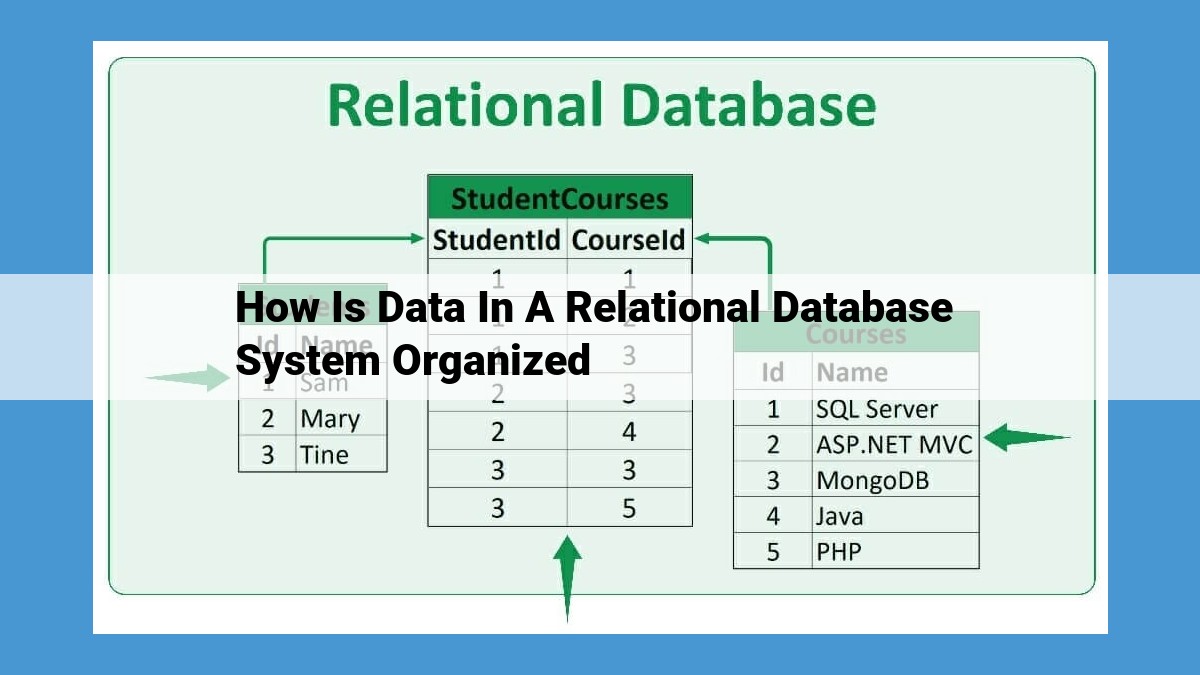
Data in a relational database system is meticulously organized using tables, which act as the fundamental structure. Tables comprise rows and columns, where rows represent individual records and columns define data attributes. Data types ensure data integrity, while primary keys guarantee the uniqueness of rows. Foreign keys establish relationships between tables, allowing for data normalization to eliminate redundancy. The relational model provides the conceptual framework, guiding the organization of tables and data within the database. Schemas define the structure of tables, columns, and data types.
Tables: The Cornerstone of Data Organization
In the digital realm, data is the lifeblood of countless applications and processes. To harness this power effectively, data needs to be organized and structured in a way that enables efficient storage, retrieval, and analysis. Tables serve as the fundamental building blocks for this data organization, providing a solid foundation for robust data management systems.
Understanding Tables
Imagine a table as a meticulously organized spreadsheet. It consists of rows and columns, where each row represents an individual data record, such as a customer’s information or a product’s details. Columns, on the other hand, define the specific characteristics of each data record, such as the customer’s name, address, or the product’s price.
Rows and Primary Keys
Each row in a table is unique and is identified by a primary key. The primary key is a value or combination of values that uniquely distinguishes one row from all others in the table. This ensures that each record is easily identifiable and can be retrieved quickly.
Columns and Data Types
Columns in a table define the specific attributes of the data being stored. Each column has a data type, which specifies the type of data that can be entered into that column. Common data types include text, numbers, dates, and Boolean (true/false) values. Data types play a crucial role in maintaining data integrity, ensuring that only valid data is stored in the table.
Example: Customer Table
Consider a customer table in a database. Each row in this table represents a unique customer, and the customer ID serves as the primary key. The table contains columns such as customer name, address, phone number, and email address. Each of these columns has a specific data type, ensuring that the data entered is valid and consistent across all customer records.
Tables are the cornerstone of data organization, providing a structured and efficient way to store and manage data. By understanding the concepts of rows, columns, data types, and primary keys, you can effectively design and implement tables that meet the specific requirements of your data management needs. This solid foundation is essential for building robust and reliable data systems that support critical business processes and drive informed decision-making.
Rows: Individual Records Within a Table
In the realm of relational databases, tables reign supreme as the cornerstone of data organization. But within these tabular structures, rows emerge as the unsung heroes, representing the individual data records that bring life to your datasets.
Each row acts as a unique snapshot of a particular entity, capturing its distinct attributes within different columns. An apt analogy would be a spreadsheet, where each row corresponds to a different customer, product, or transaction, while the columns represent their respective characteristics, such as name, price, or order date.
Rows are intertwined with primary keys, the unique identifiers that distinguish one record from another within the same table. Think of primary keys as the “passports” for your data, ensuring that each row can be unequivocally identified. This is crucial for maintaining the integrity and accuracy of your data, preventing duplicates and ensuring that you can retrieve specific records effortlessly.
In simpler terms, imagine a table of customer records. Each row represents an individual customer, with their name, address, and other pertinent details arranged in columns. The customer’s unique ID number serves as the primary key, making it a breeze to locate and update their information as needed.
Columns: Defining the Attributes of Data
In the realm of data management, where orderliness reigns supreme, tables serve as the sturdy foundation upon which data is meticulously organized. These tables are meticulously structured into rows and columns, each playing a vital role in maintaining data integrity and accessibility.
Columns, the vertical pillars of a table, define the attributes or characteristics of the data stored within. Each column possesses a unique name that encapsulates the specific information it holds. For instance, in a table containing customer details, you might encounter columns such as “Customer ID,” “Name,” “Email,” and “Address.”
The data type of a column determines the permissible values it can hold. These data types range from numbers (integer, float, date) to text (string) and specialized categories like Boolean (true/false) and enum (predefined options). By enforcing data type constraints, databases ensure that only valid and consistent data is entered, safeguarding against erroneous entries.
Furthermore, columns play a crucial role in establishing primary and foreign keys. A primary key is a column or a combination of columns that uniquely identifies each row within a table, akin to a distinctive fingerprint. It prevents duplicate records and guarantees data integrity.
Foreign keys, on the other hand, link rows across multiple tables, establishing relationships between them. They reference the primary key of another table, thereby creating logical connections and facilitating data normalization—a process that minimizes data redundancy and maintains data consistency across multiple tables.
Data Types: The Guardians of Data Integrity
In the realm of Relational Database Management Systems (RDBMS), data types stand as the sentinels of data integrity, ensuring that data remains accurate, consistent, and fit for its intended purpose. Different data types, like knights with specialized armor, serve specific roles in safeguarding your precious data.
Numeric Types: Precision for Numbers
Numeric data types, including integer, decimal, and float, are designed to handle numerical values. Integers represent whole numbers, while decimals allow for fractional parts. Floats provide greater precision for very large or very small numbers. These types enforce numeric constraints, ensuring that data conforms to expected ranges and precision.
Character Types: Strings with Personality
Character data types, such as char and varchar, accommodate textual data. Char defines fixed-length strings, ensuring consistency in storage, while varchar allows for varying string lengths, providing flexibility for diverse text input. These types impose character limits, preventing data overflow and ensuring that text data remains manageable.
Date and Time Types: Capturing Time’s Essence
Date and time data types, like date, time, and timestamp, enable the precise recording of temporal information. They distinguish between dates, times, and timestamps, capturing both the calendar day and the specific moment of occurrence. These types ensure that temporal data is stored consistently and can be easily compared and manipulated.
Boolean Type: True or False, No In-Between
The boolean data type represents logical values, allowing data to be categorized as either true or false. This simple yet powerful type finds applications in filtering, searching, and decision-making. It ensures that Boolean data is stored concisely and without ambiguity.
Composite Types: Complex Structures for Rich Data
Composite data types, such as arrays and objects, provide a way to store structured data within a single field. Arrays hold collections of similar elements, while objects combine multiple data types into complex structures. These types enable the representation of hierarchical or complex data in a structured and efficient manner.
By selecting the appropriate data types for each field, you strengthen the integrity of your database. Data is stored in a consistent and valid format, minimizing errors and ensuring the reliability of your information. Data types act as the foundation upon which the integrity of your data rests, safeguarding it from corruption and ensuring its usefulness in your applications.
Primary Keys: The Guardians of Unique Identities in Relational Databases
Imagine a chaotic library with countless shelves, each filled with a jumble of books. Without any system or organization, finding a specific book could be a needle in a haystack. Just as libraries need a way to organize their books, relational databases use primary keys to establish order and identify each row of data uniquely.
Primary keys are like the guardians of uniqueness within a table, ensuring that no two rows possess the exact same values in that key column. They act as a unique fingerprint for each row, allowing us to pinpoint and access specific data records with ease.
Primary keys are usually assigned automatically by the database system or explicitly defined by database designers. They can be simple values like an employee’s ID number or more complex combinations of multiple columns, such as a combination of a customer’s last name and zip code.
The primary key is not just a random number, but a carefully chosen value that serves a specific purpose. It’s like a master key that unlocks a specific row of data, allowing us to retrieve it quickly and efficiently. Without primary keys, databases would be a tangled mess of duplicate and indistinguishable records, making it a nightmare to manage and retrieve data effectively.
Foreign Keys: The Bridges That Connect Your Data
In the world of data, relationships are crucial. And when it comes to organizing your data in a relational database management system (RDBMS), foreign keys are the key to establishing those relationships.
Think of foreign keys as the invisible threads that weave your tables together, allowing them to communicate and share information. They work hand-in-hand with primary keys, the unique identifiers that distinguish each row in a table.
How Foreign Keys Work
Let’s say you have two tables: Customers and Orders. Each customer has a unique CustomerID, while each order has a unique OrderID. To link these tables and show which customers placed which orders, you use a foreign key.
In the Orders table, you’ll add a CustomerID column. This column will store the CustomerID of the customer who placed the order. By referencing the CustomerID in the Customers table, you establish a one-to-many relationship, meaning one customer can have multiple orders, but each order belongs to only one customer.
Data Normalization: Breaking Up Redundancies
Foreign keys play a vital role in data normalization, a process that eliminates duplicate and redundant data. Without foreign keys, you might end up storing customer information multiple times in different tables. For example, if you have a table for sales reps and another for customers, you might have to repeat customer information in both tables.
Using foreign keys, you can normalize your data by referencing the CustomerID in the SalesReps table to the CustomerID in the Customers table. This eliminates the need to duplicate customer information and ensures that any changes to customer data are reflected in all related tables.
Foreign keys are the backbone of data relationships in RDBMS. They link rows across tables, facilitate data normalization, and provide a solid foundation for efficient data management. By understanding and using foreign keys effectively, you can create a well-structured database that supports your business needs and ensures data integrity.
The Relational Model: A Framework for Data Management
In the realm of data organization, the relational model stands as a cornerstone, providing a structured and coherent approach to managing information within relational database management systems (RDBMSs). It’s like a well-organized library, where data is meticulously arranged into tables, rows, and columns, allowing for efficient retrieval and analysis.
At the heart of the relational model lies a fundamental concept: data is represented as tables, akin to spreadsheets. Each table comprises vertical columns that define specific data attributes, such as “customer name” or “product category.” Horizontally, tables are divided into rows, each representing an individual record or entity. For instance, a customer table may contain rows for each customer, with columns for their name, address, and contact details.
The relational model also introduces the notion of primary keys. A primary key is a unique identifier that distinguishes each row within a table. Imagine it as a fingerprint for each record, ensuring that no two customers or products can share the same identity. This feature is crucial for maintaining data integrity and allowing for quick and accurate lookups.
To facilitate relationships between tables, the relational model employs foreign keys. These are columns that reference primary keys in related tables, establishing connections between data. For example, an order table may include a foreign key that references the customer table, linking orders to specific customers. This allows us to easily retrieve all orders placed by a particular customer or identify the customer associated with an order.
Overall, the relational model provides a flexible and powerful framework for organizing and managing data. It enables data to be stored in a consistent and structured manner, facilitates relationships between entities, and ensures data integrity through primary and foreign keys. By adhering to the principles of the relational model, database designers can create robust and efficient databases that support complex queries and data analysis.
Schema: The Blueprint for Database Structure
- Discuss the concept of a schema and how it defines the structure of tables, columns, and data types.
Schema: The Blueprint for Database Structure
In the realm of data management, the schema serves as the blueprint for a database, dictating its structure and organization. Just as an architect’s schema defines the layout of a building, a database schema establishes the framework for storing and organizing data.
At its core, a schema defines the following:
- Tables: The fundamental units of data storage, structured into rows and columns.
- Columns: Define the data attributes of each table, including their data types and properties.
- Data Types: Specify the format and permissible values for data in each column, ensuring data integrity.
The schema ensures that data is organized and accessible in a meaningful way. It acts as a guide for the database, enabling it to interpret and process data efficiently. Without a schema, a database would be a chaotic collection of unorganized data, making it difficult to extract meaningful insights.
A schema’s significance extends beyond its role in data organization. It also facilitates:
- Data Validation: The schema enforces data integrity by ensuring that data conforms to the specified data types and constraints.
- Data Relationships: The schema defines relationships between tables using foreign keys, allowing data to be linked and accessed across multiple tables.
- Data Normalization: The schema helps eliminate data duplication and inconsistencies by adhering to normalization principles.
By providing a comprehensive blueprint for database structure, the schema empowers organizations to manage their data effectively, ensuring its quality, accessibility, and reliability.
Normalization: Eliminating Data Duplication
Imagine you’re a data scientist tasked with managing a vast database of customers and their orders. As you dive into the data, you realize that some customers have multiple entries, leading to inconsistencies and potential errors. To remedy this, you embark on a journey of data normalization.
Normalization is a crucial concept in database management that ensures data integrity and efficiency. It involves organizing data into tables and establishing relationships between them to eliminate redundant information and inconsistency. Here’s how it works:
-
First Normal Form (1NF): Each row in a table represents a unique data record, and columns contain atomic values (not divisible into smaller meaningful units).
-
Second Normal Form (2NF): Every non-key column (not part of the primary key) is fully dependent on the primary key, meaning it cannot be derived from other non-key columns.
-
Third Normal Form (3NF): No non-key column is transitively dependent on another non-key column. In other words, the primary key uniquely determines all other columns.
The benefits of normalization are numerous:
-
Reduced Data Redundancy: By eliminating duplicate data, normalization minimizes storage space and reduces the risk of data inconsistencies.
-
Improved Data Integrity: Normalization ensures that each piece of information is stored only once and is consistent across the database. This prevents data corruption and improves data reliability.
-
Faster Query Performance: Normalized databases are more efficient for querying, as they avoid unnecessary data joins and reduce the amount of data that needs to be processed.
-
Enhanced Data Consistency: Normalization establishes clear relationships between tables, ensuring that updates and changes are propagated consistently throughout the database.
By following the principles of normalization, data scientists can create well-structured databases that are accurate, efficient, and easy to manage. It’s akin to organizing a well-stocked library, where each book has its designated place on the shelf, making it easy to find and retrieve.
